|

고객의 요구는 다양하면서도 비대면 현상과 개인화의 특징이 뚜렷하고, 제품 수명은 단축되는 반면 부가가치는 높아지고 인건비는 급등하는 등 시장환경이 아주 빠른 속도로 바뀌고 있다. 과거 산업혁명은 흐름의 추세를 근간으로 예측이 가능했다면, 4차 산업혁명 및 앞으로 전개될 초 인류 사회는 전혀 경험하지 못한 새로운 시장환경이 펼쳐 질 조짐이다.
가격경쟁의 변화로는 개발도상국의 추격, 무역장벽에 따른 해외 생산화, 무역 불균형, EC 통합 등을 들 수 있다. 또한 기술 환경의 변화로는 제품의 서비스화, 마이크로 일렉트로닉스 (Microelectronics)화, 네트워크화, 데이터 베이스 관리의 발전 등이 있다. 이와 같은 외부환경의 변화는 기업의 생산성 저하, 재고의 증가, 결품의 발생, 빈번한 품질 클레임 발생, 이익의 저하 등을 가져 오고 있다. 그게 현실이다.
그런데 문제는 현 시대의 제조업들이 아직도 과거 산업혁명 시대처럼 경영 기법의 추세에 매몰되고 있다는 것이다. 환경 변화에 적응하며, 경영 기법을 변화시키는 “맞춤 생산 시대 제조업의 생산 대응 역량”을 실현시키기 위해서는 “인공지능 스마트팩토리 구축”이 필수적이다. 그럼에도 불구하고 이와 같은 새로운 개념을 받아드려야 하는 제조업의 조직문화가 새로움의 최대 적인 “편견”에 빠져 있는 듯하다. 영국인이 가장 사랑하는 여류 작가, 제인 오스틴의 “오만과 편견”이 영상으로 스쳐가는 것은 꼭 그 것만은 아닐 것이다.
인공지능 기반 스마트 팩토리를 구축하기 위해서는 제조 현장의 비정형 데이터를 구조화(Structurization: 構造化)하는 역량이 핵심으로 떠오르고 있다. 비정형 데이터(unstructured data)란 그림이나 영상, 소리, 자연어, 문서처럼 형태와 구조가 다른 구조화 되지 않은 데이터를 말하며, 일정한 규격이나 형태를 지닌 숫자 데이터(numeric data) 기반 경영정보시스템(MIS: Management Information System)과는 다르다.
기존의 컴퓨터 시스템(ERP,MES)은 연산과 처리 절차가 숫자 데이터 중심으로 설계되어 있기 때문에 이름이나 성별과 같은 문자 변수는 숫자로 변환해 처리하는 방법을 주로 사용했다. 그러나 이런 방법은 트위터나 블로그처럼 모바일과 온라인에서 생성되는 대규모의 비정형 데이터에 적용하는 것이 불가능하며, 특히 제조 현장의 작업자 동작 정보(Behavior Information), 로봇의 동작 이미지 정보, 다양한 사물의 움직임을 관찰하는 이미지 등 다양한 비정형 데이터가 각종 정보통신 기술의 발달로 쏟아져 나오고 있는 현실에 대응하기에는 부적절하게 설계되어 있다.
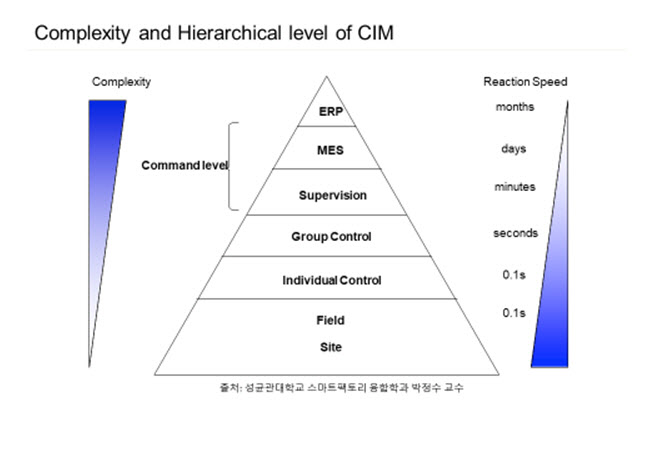
이와 같은 비정형 데이터를 스마트 팩토리에서 활용하기 위해서는 과거 산업혁명에서 기계화와 자동화를 도입하기 위해서 컴퓨터를 활용(CIM: Computer Integrated Manufacturing)하였듯이, 4차 혁명시대에는 지능화와 자율화를 실현시키기 위해서 비정형 데이터를 활용하기 위한 데이터의 구조화 기술과 인공지능 기술을 융·통합시켜 제조 현장에 녹여내야 한다. 그것이 바로 인공지능 스마트팩토리의 출발이기 때문이다. 아래 그림은 CIM의 복잡성과 계층을 보여주고 있다.
|
비정형 데이터를 구조화하는 방법은 그 대상이 매우 다양하다. 예를 들어 인터넷을 이용하는 과정에서 생성되는 웹 로그(web log) 정보나 검색어로부터 유용한 정보를 추출하는 웹을 대상으로 한 데이터 마이닝의 웹 마이닝(web mining), 어떤 사안이나 인물, 이슈, 이벤트에 대한 사람들의 의견이나 평가, 태도, 감정 등을 분석하는 오피니언 마이닝(opinion mining), 그리고 대규모의 문서(text)에서 의미 있는 정보를 추출하는 텍스트 마이닝(text mining)이 있다.
텍스트 마이닝은 분석 대상이 비구조적인 문서정보라는 점에서 데이터 마이닝과 차이가 있으며, 텍스트 분석(text analytics), 텍스트 데이터베이스로부터 지식 발견(KDT, Knowledge Discovery in Textual Database), 문서 마이닝(document Mining) 등으로 불리기도 한다. 텍스트 마이닝은 정보 검색, 데이터 마이닝, 기계 학습(machine learning), 통계학, 컴퓨터 언어학(computational linguistics) 등이 결합된 학제적(interdisciplinary) 분야이다.
이는 분석 대상이 형태가 일정하지 않고 다루기 힘든 비정형 데이터이므로 인간의 언어를 컴퓨터가 인식해 처리하는 자연어 처리(NLP, natural language processing) 방법과 관련이 깊다. 좀 더 구체적으로 문서 분류(document classification), 문서 군집(document clustering), 메타데이터 추출(metadata extraction), 정보 추출(information extraction) 등으로 구분한다. 아래 그림은 비정형 데이터의 양이 매년 60~80% 상승하고 있다는 것이다.
|
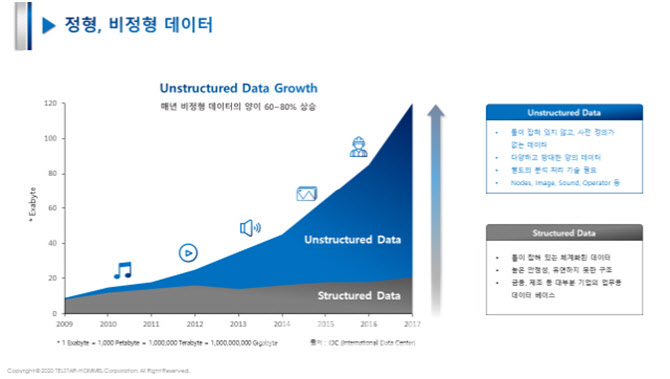
이처럼 제조 현장에 비정형 데이터의 양이 매년 급 상승하고 있기 때문에 그것을 활용하느냐 못하느냐가 제조업의 경쟁력으로 변환되고 있는 시대가 4차 산업혁명의 시대이고, 그래서 인공지능 스마트 팩토리를 구축하여야 한다.
기본적으로 비정형 데이터를 구조화하여 제조현장에 활용하기 위해서는 통계학의 방법론인 판별분석(discriminant analysis)과 군집분석(clustering)과 유사한 개념으로 분석 대상이 숫자가 아닌 이미지나 텍스트라는 점을 알아두어야 한다. 통상 문서 분류는 사전에 분류 정보를 알고 있는 상태에서 주제에 따라 분류하는 방법이며 문서 군집은 분류 정보를 모르는 상태에서 수행하는 방법이다. 이를 지도 학습(supervised learning), 자율 학습(unsupervised learning)이라고 부르는데, 데이터 마이닝에서도 동일한 의미로 사용하고 있다.
정형 데이터가 판단의 준거를 제시해 온 과거 산업혁명과 달리 새로운 산업혁명, 4차 산업혁명 시대에는 비정형 데이터까지도 범위를 확장하여 제조 경영에 활용하고자 하는 새로운 제조업 경영전략이 인공지능 스마트 팩토리 구축과 환경 조성에 있다는 사실을 직시해야 한다.
따라서 비정형 데이터를 구조화시키고, 제조 현장에 활용하여 자율화된 유연성을 확보해 나가는 것이 인공지능 기반 스마트팩토리의 목적이다. 그것이 바로 지능화의 출발이며, 데이터 라벨링 작업이 인공지능 스마트 팩토리의 기본이라면, 비정형 데이터의 구조화는 인공지능을 활용하는 제조 역량의 활성화 작업이다.
그러므로 디지털 대전환(Digital Transformation) 시대의 준거(準據 , criterion)는 비정형 데이터를 얼마나 잘 활용하느냐이다. 디지털 기술의 핵심도 비정형 데이터 관리 기술로 바뀌어가고 있으며, 더 나아가 빅데이터 관리 기술이 우리 사회를 ‘초연결 사회’로 바꿔가고 있다.
사람과 사물 등 모든 것이 연결돼 의료, 교육, 제조 등 전 영역에서 비대면 시장과 개인화 고객의 원츠와 니즈(Wants & Needs)가 ‘살아가는 방식’을 변화시키고 있다. 초연결 사회는 이제껏 생각하지 못했던 새로운 가치를 실현할 수 있게 한다. 그래서 사회에서 요구되는 가치를 인지하고 실제로 구현하는 과정에서 “(스마트 폰) 사용자의 경험”이 존재하듯이 개인화 고객과 시장에 “맞춤형 비즈니스”를 실현하는 과정에는 인공지능 기반 스마트팩토리가 있다.