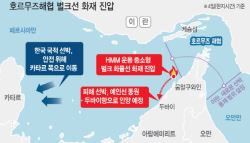
.png)




|
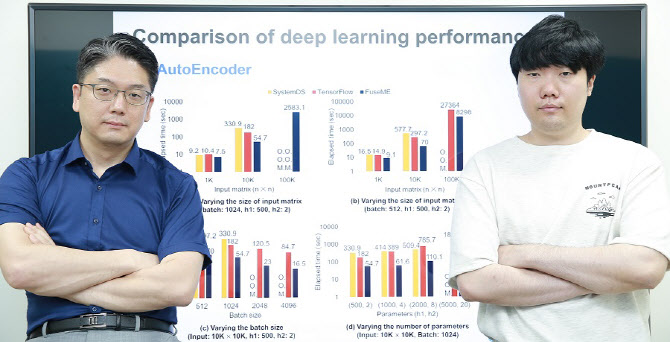
오늘날 광범위한 산업 분야들에서 사용되는 딥러닝 모델들은 대부분 구글의 텐서플로우(TensorFlow)나 IBM의 시스템DS와 같은 기계학습 시스템을 이용해 처리된다.
일반적으로 딥러닝 모델은 행렬 곱셈, 행렬 합, 행렬 집계 등의 많은 행렬 연산자들로 구성된 방향성 비순환 그래프(DAG) 형태의 질의 계획으로 표현돼 기계학습 시스템에 의해 처리된다.
모델과 데이터의 규모가 클 때는 일반적으로 DAG 질의 계획은 수많은 컴퓨터로 구성된 클러스터에서 처리된다. 클러스터의 사양에 비해 모델과 데이터의 규모가 커지면 처리에 실패하거나 시간이 오래 걸리는 근본적인 문제가 있었다.
지금까지는 더 큰 규모의 모델이나 데이터를 처리하기 위해 단순히 컴퓨터 클러스터의 규모를 증가시키는 방식을 주로 사용했다.
그러나, 김 교수팀은 DAG 질의 계획을 구성하는 각 행렬 연산자로부터 생성되는 일종의 ‘중간 데이터’를 메모리에 저장하거나 네트워크 통신을 통해 다른 컴퓨터로 전송하는 것이 문제의 원인임에 착안했다.
중간 데이터를 저장하지 않거나 다른 컴퓨터로 전송하지 않도록 여러 행렬 연산자들을 하나의 연산자로 융합(fusion)하는 세계 최고 성능의 융합 기술인 FuseME를 개발해 문제를 해결한 것이다.
현재까지의 기계학습 시스템들은 낮은 수준의 연산자 융합 기술만을 사용하고 있었다. 가장 복잡한 행렬 연산자인 행렬 곱을 제외한 나머지 연산자들만 융합해 성능이 별로 개선되지 않거나, 전체 DAG 질의 계획을 단순히 하나의 연산자처럼 실행해 메모리 부족으로 처리에 실패하는 한계가 있었다.
김 교수팀이 개발한 FuseME 기술은 수십 개 이상의 행렬 연산자들로 구성되는 DAG 질의 계획에서 어떤 연산자들끼리 서로 융합하는 것이 더 우수한 성능을 내는지 비용 기반으로 판별해 그룹으로 묶는다.
이후 클러스터의 사양, 네트워크 통신 속도, 입력 데이터 크기 등을 모두 고려해 각 융합 연산자 그룹을 메모리 부족으로 처리에 실패하지 않으면서 이론적으로 최적 성능을 낼 수 있는 CFO라 불리는 연산자로 융합함으로써 한계를 극복했다. 이때, 행렬 곱 연산자까지 포함해 연산자들을 융합하는 것이 핵심이다.
김 교수 연구팀이 FuseME 기술을 종래 최고 기술로 알려진 구글의 텐서플로우나 IBM의 시스템DS와 비교한 결과 딥러닝 모델의 처리 속도는 최대 8.8배 향상됐으며 텐서플로우나 시스템DS가 처리할 수 없는 훨씬 더 큰 규모의 모델과 데이터를 처리하는 데 성공했다.
또한 FuseME의 CFO 융합 연산자는 종래의 최고 수준 융합 연산자와 비교해 처리 속도를 최대 238배 향상시키고 네트워크 통신 비용을 최대 64배 감소시키는 사실을 확인했다.
김 교수는 “연구팀이 개발한 새로운 기술은 딥러닝 등 기계학습 모델의 처리 규모와 성능을 획기적으로 높일 수 있어 산업적 측면에서 파급 효과가 매우 클 것으로 기대한다?라고 말했다.
이번 연구에는 김 교수의 제자이자 현재 GraphAI(그래파이) 스타트업의 공동 창업자인 한동형 박사가 제1 저자로, 김 교수가 교신저자로 참여했으며 지난 16일 미국 필라델피아에서 열린 데이터베이스 분야 최고 국제학술대회 중 하나인 ACM SIGMOD에서 발표됐다.