



|
개인정보위는 지난해 12월부터 ‘AI 프라이버시 민·관 정책협의회’ 리스크 평가 분과 논의를 중심으로 리스크 관리 모델을 마련했다. 리스크 관리 모델은 국내외 학계·정부·연구기관 등에서 논의되고 공감대가 형성되고 있는 AI 데이터 처리 특성, 프라이버시 리스크 유형, 리스크 경감방안 및 관리체계, 기업 사례 등을 집대성해 안내하는 자료다.
먼저 ‘AI 프라이버시 리스크 관리 절차’에 따르면 △AI의 구체적 유형·용례 파악 △구체적 리스크 식별 △중대성 등 정성적·정량적 리스크 측정 △리스크에 비례하는 안전조치 마련을 통해 체계적으로 관리할 수 있다. 리스크의 조기 발견과 완화를 위해 ‘개인정보 보호 중심 설계(PbD)’ 관점에서 AI 모델 및 시스템의 기획·개발 단계부터 이뤄지는 것이 바람직하다. 이후 시스템 고도화 등 환경 변화에 따라 주기적·반복적으로 이뤄지는 것이 권장된다.
다음으로 ‘AI 프라이버시 리스크 유형’을 예시로 제시했다. 국내외 문헌조사와 기업 인터뷰 등을 통해 파악한 AI 기술의 고유한 특성 및 데이터 요구사항 등으로 인해, 새롭게 나타나는 정보 주체의 권리 침해와 개인정보 보호법 위반 리스크 등을 중점적으로 다뤘다. 특히 서비스 제공 단계는 ‘생성 AI’와 ‘판별 AI’를 구분함으로써 AI 용례 및 유형에 따른 구체성을 더했다.
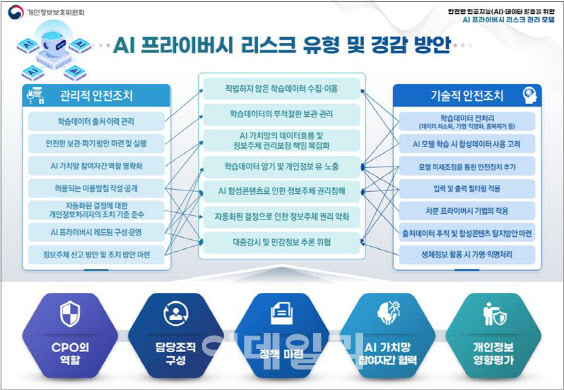
아울러 ‘AI 프라이버시 리스크 경감 방안’으로 관리적·기술적 안전조치도 안내했다. 다만 모든 경감조치를 필수적으로 취해야 하는 것은 아니며, 구체적으로 리스크를 식별하고 측정한 결과 등 개별 맥락에 따라 최적의 안전조치 조합을 마련해 시행할 수 있도록 안내했다.
관리적 안전 조치에는 △학습데이터 출처·이력 관리 △허용되는 이용방침 마련 △AI 프라이버시 레드팀을 통한 개인정보 침해유형 테스트 및 조치 △부적절한 답변 등에 대한 정보주체 신고방안 마련 등이 포함된다. 또한 학습데이터에 민감한 정보가 포함될 개연성이 높거나 대규모 개인정보가 포함되는 경우 △개인정보 영향평가 수행도 권장된다.
기술적 안전 조치에는 △AI 학습데이터 전처리(불필요한 데이터 삭제, 가명·익명화, 중복제거 등) △AI 모델 미세조정을 통한 안전장치 추가 △입력·출력 필터링 적용 △차분 프라이버시 기법의 적용 등이 포함된다. 개인정보위는 한국어가 적용된 AI 모델의 특수성도 고려하기 위해 리스크 경감기술 효과 분석을 위한 정책연구도 진행했다.
마지막으로 ‘AI 프라이버시 리스크 관리 체계’를 제시했다. AI 환경에서는 개인정보 보호, AI 거버넌스, 사이버 보안, 안전·신뢰 등 다양한 디지털 거버넌스 요소가 상호 연관된다. 이에 따라 전통적 거버넌스의 재편과 함께 개인정보 보호책임자(CPO)의 주도적 역할·책임감이 중시된다. 또한 리스크에 대한 다각적·전문적 평가를 수행할 수 있는 담당조직을 구성하고, 체계적 리스크 관리를 보장하는 정책을 마련하는 것이 바람직하다.
개인정보위는 추후 AI 기술 발전, 개인정보 관련 법령 제·개정, 글로벌 동향 등을 고려해 리스크 관리 모델을 지속적으로 업데이트할 계획이다. 이와 함께 소규모 조직, 스타트업, 미세조정 및 검색증강(RAG) 등 AI 개발 유형 등 세부 영역 등에 특화한 안내자료도 조만간 구체화할 예정이다.
이 밖에도 사전적정성 검토제, 규제샌드박스, 개인정보 안심구역 등 혁신지원 제도를 통해 AI 기업과 수시로 소통하면서 기술의 발전 양상과 기업 애로사항을 모니터링할 방침이다. 이를 통해 축적한 사례와 경험을 토대로 AI 시대에 맞게 개인정보 보호법을 정비하는 작업도 추진할 계획이다.
고학수 개인정보위원장은 “개인정보와 비개인정보가 총체적으로 활용되고 기술 발전이 지속되는 AI 영역은 불확실성이 높기 때문에, 일률적 규제보다는 합리적·비례적 관리를 통해 리스크를 총체적으로 최소화하는 것이 필요하다”며 “리스크 관리 모델이 AI 기업 등에서 프라이버시 리스크를 이해하고 체계적으로 관리하는 데 도움이 되길 바란다”고 말했다.






