

|
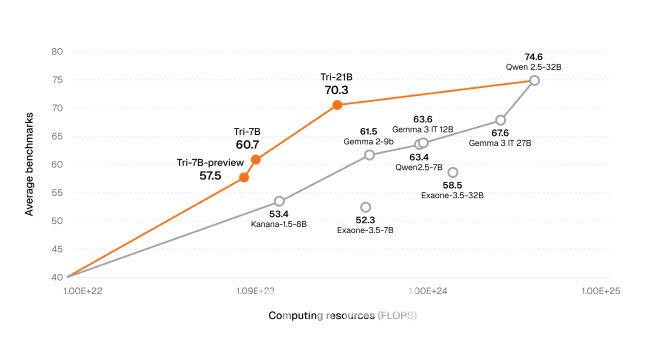
트릴리온랩스의 독보적인 기술력으로 LLM 엔진부터 완전한 사전학습 방식으로 개발된 이번 모델은 고정밀 추론이 필요한 작업에서 강력한 성능을 발휘하도록 설계되었다. 수학과 코딩 등 단계적 사고가 요구되는 문제에 대해 구조화된 답변을 생성하는 생각사슬 구조를 채택했으며, 특히 트릴리온랩스만의 기술력인 언어 간 상호학습 시스템(XLDA)을 적용했다. XLDA는 영어 기반 지식을 한국어 및 일본어와 같은 저자원 언어로 효과적으로 전이하는 데이터 학습 방법론으로, 기존 대비 1/12 수준으로 학습 비용을 대폭 절감하는 혁신을 이뤄냈다.
트릴리온-21B는 종합지식(MMLU), 한국어 언어 이해(KMMLU), 수학(MATH), 코딩(MBPP Plus) 등 고난도 추론 중심 벤치마크에서 알리바바의 Qwen 3, 메타 LLaMA 3, 구글의 Gemma 3 등 글로벌 대표 중형 모델과 견줄만한 성능을 보였다. 특히 추론능력 검증(MMLU)에서는 77.93(CoT적용시 85)점, 수학(MATH)에서 77.89점, 코딩 영역(MBPP Plus)에서 75.4점의 정확도를 기록하며 실제 문제 해결 능력에서도 강점을 입증했다.
주요 한국어 벤치마크에서도 두각을 드러냈다. 한국문화의 이해도를 측정하는 해례(Hae-Rae)에서 86.62점, 한국어 지식과 추론능력(KMMLU)에서 62점(CoT적용시 70)을 기록, 글로벌 모델 대비 월등히 높은 점수를 기록하며 어휘와 문맥 이해, 문화적 맥락 반영에서 독보적인 한국어 이해능력을 보였다. 또한 금융, 의료, 법률 등 높은 신뢰도가 요구되는 분야에서도 안정적인 결과를 도출해, 산업 전반에 걸친 적용 가능성을 높였다.
신재민 트릴리온랩스 대표는 “트리(Tri)-21B는 플라이휠 구조를 통해 70B급 대형 모델의 성능을 21B에 효과적으로 전이해 모델 사이즈와 비용, 성능 간 균형에서 현존하는 가장 이상적인 구조를 구현했다”고 말했다.





![결혼 앞둔 예비신부 사망…성폭행 뒤 살해한 그놈 정체는 [그해 오늘]](https://image.edaily.co.kr/images/vision/files/NP/S/2026/03/PS26031200001t.jpg)