
.png)




|
LG AI연구원은 19일 서울 강서구 마곡 LG사이언스파크에서 ‘LG AI 토크 콘서트 2023’을 열고, 자체 초거대 AI ‘엑사원 2.0‘을 소개했다. 엑사원 2.0은 2021년 12월 첫 선을 보인 ‘엑사원’의 진화된 버전이다. △고품질의 데이터 학습 △비용 절감 △사용자 니즈에 맞춘 커스텀 모델 지원이 특징이다.
배경훈 LG AI 연구원장은 “산업현장에서는 현재 생성형AI에 만족하지 못하고 있다”며 “생성된 결과에 대한 신뢰도가 높지 않고, 대규모 모델을 학습하고 운영하는 과정에서 많은 비용이 발생하며 기업 내부 데이터 유출에 대한 우려도 있어서다”고 했다.
|

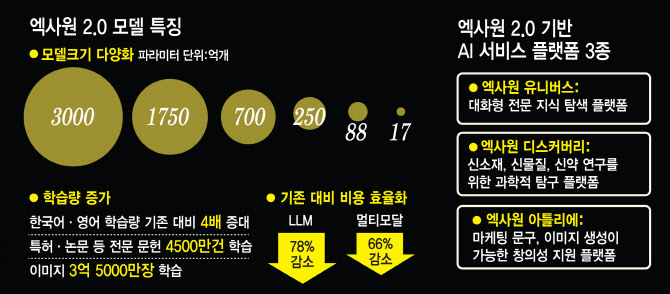
비용 효율화에도 주력했다. 거대언어모델(LLM)은 이전 대비 추론 시간을 25% 단축하고 메모리 사용량을 70% 감소시켜 총 약 78%의 비용 절감 효과를 내도록 했다. 텍스트와 이미지를 혼용한 멀티모달 모델의 비용은 총 66% 줄였다.
사용자 니즈에 맞춰 모델 크기와 구동 환경도 선택할 수 있게 했다. 국내 초거대 AI 모델 중 가장 큰 3000억개 파라미터를 갖춘 모델부터 17억개 파라미터를 가진 모델까지 크기별로 총 6가지 모델을 제공한다. 또, 고객 데이터 보안을 위해 학습 과정을 미세 조정하는 파인 튜닝과, AI 인프라를 고객이 보유한 서버에 직접 설치하는 구축형(온프레미스) 및 사설 클라우드 방식도 지원한다.
◇전문가를 위한 챗봇형 AI 유니버스 등 3개 플랫폼 공개
LG AI연구원은 이날 엑사원 기반 AI 서비스 플랫폼으로, 전문가를 위한 대화형 AI ’엑사원 유니버스‘를 공개했다. 배 원장은 “유니버스는 생산형AI 기술의 핵심인 LLM을 통해 질문에 전문적 답변을 생성해 주고, 나아가 최신 기술을 연구하거나 기업의 전문 업무를 도와주는 플랫폼”이라고 소개했다.
일반적인 대화형 AI와 달리, 사전 학습한 데이터는 물론 각 도메인별 최신 전문 데이터까지 포함해 근거를 찾아내며 추론한 답변을 생성하는 게 특징이다. 예컨대 “AI 모델 개발 시 할루시네이션을 어떻게 극복해야 할지 알려줘”라고 질문하면, “텍스트뿐 아니라 비주얼 데이터를 함께 사용하는 것이 효과적이다”는 내용의 인사이트를 제공하는데, 이때 근거 카드를 함께 보여준다. 근거 카드를 클릭하면 관련 내용을 포함한 논문이 뜬다.
|

기존 생성형AI는 데이터를 바탕으로 답변을 바로 생성하고 후처리 과정을 거쳐 답변을 내놓는다. 근거의 전체적인 밑그림을 그리기 어렵기 때문에 거짓 답변을 만드는 환각문제가 발생하기 쉬운 이유다.
반면, 유니버스는 데이터베이스 내에서 관련 있는 문서를 먼저 파악하고, 선택한 문서를 상세히 보고 근거를 추론한다. 이후 종합적, 논리적 사고를 통해 답변을 구성하고 출처를 제공하는 구조를 채택했다. 배 원장은 “전문적인 데이터를 학습해서 환각현상을 줄이기도 했지만, 구조적인 측면에서도 처음부터 질문한 내용과 가장 유사한 문서를 찾는 방식으로 정확도를 높였다”고 설명했다.
이문태 어드밴스드 ML랩장은 “도메인 전문가들이 유니버스 플랫폼에서 사용한 모델과 오픈AI의 인스트럭트GPT, 메타의 갤럭티카의 답변을 비교한 결과, 유니버스 답변이 가장 전문가에 가깝다는 평가를 내렸다”고 했다. 해당 결과는 AI 분야 권위 있는 국제학술대회인 ICML 2023에도 제출됐다.
창의성 지원 플랫폼 ’엑사원 아틀리에’도 선보였다. 아틀리에는 이미지 생성과 이미지 이해에 특화된 기능을 제공한다. 이미지를 보고 적절한 설명 문구를 생성해 낼 수 있어, 기업 내 마케팅 담당자가 광고 문구를 만드는 데 쓸 수도 있고, 일반인들이 소셜미디어에 사진 업로드 시 필요한 문구를 얻는 데 쓸 수도 있다.
LG AI연구원은 과학적 지식 발견 플랫폼 ‘엑사원 디스커버리’도 공개했다. 디스커버리는 먼저 신소재·신물질·신약 관련 탐색에 적용됐다.
이날 한세희 머터리얼 인텔리전스랩장은 친환경 배터리 개발에 활용할 수 있는 첨가제 소재의 개발을 주제로, 유니버스와 디스커버리를 연계해 AI에 질문하며 △전문 문헌 검토 △분자 정보 추출 △소재 구조 설계(UMD) △소재 합성 예측(NCS) 등 후보 소재를 찾아내 합성 결과를 예측하는 과정을 시연했다.



!['개과천선' 한국판 패리스 힐튼 서인영의 아파트[누구집]](https://image.edaily.co.kr/images/vision/files/NP/S/2026/05/PS26050300075t.jpg)


