
.png)
.png)




과학기술정보통신부는 14일 이런 내용을 담은 ‘초거대 AI 경쟁력 강화방안’을 발표했다.
|
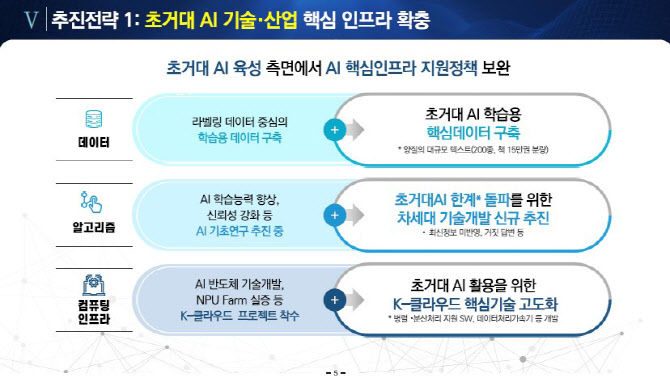
과기정통부는 초거대 AI 개발에 필요한 양질의 텍스트 데이터를 확충한다. 분야별 특화 학습용 데이터, 비영어권 시장 공략을 위한 언어 데이터(동남아·중동 등)를 오는 2027년까지 200종(책 15만권 분량) 구축한다. 또 같은 기간 한국어 성능 향상을 위한 고품질 말뭉치와 한국어 응용 말뭉치를 130종 마련한다.
최신 정보 미반영, 거짓 답변 등 초거대 AI 활용 과정에서 나타난 한계를 보완하는 기술 개발도 추진한다. 기존 딥러닝의 학습 능력·신뢰성 등을 개선하는 기초연구(~2026년, 2655억원)에 더해 논리적 리즈닝(인과관계 이해), 편향성 필터링, 모델 경량화 등의 기술을 개발한다.
초거대 AI 개발·운영에 필요한 막대한 컴퓨팅 자원을 지원하고자, 국산 AI 반도체 기반 고성능·저전력 K-클라우드가 초거대 AI에 활용될 수 있도록 AI 반도체 소프트웨어, 데이터 가속 처리 하드웨어 등을 개발·실증한다. 법률, 의료, 심리상담, 문화·예술, 학술·연구 등 민간 전문 영역에 초거대 AI를 접목해 전문가의 업무를 보조하는 ‘초거대 AI 5대 플래그십 프로젝트’도 추진된다.
또 과기정통부는 민간 차원의 투자, 신서비스 창출 등 협력 강화를 위한 ‘초거대 AI 협의회’를 구성해 운영할 방침이다. 초거대 AI 전문 인재를 양성하며, 일반 국민을 대상으로 초거대 AI 기초 활용·윤리 교육 등 리터러시를 높일 계획이다. AI 법제정비단을 운영해 초거대 AI 규제 개선 과제를 발굴하고, 지식재산권 등 기존 제도도 정비해 나간다.
이종호 과기정통부 장관은 “초거대 AI 역량이 곧 개인, 기업, 국가의 경쟁력을 좌우하게 될 것”이라며 “우리 기업의 독자적 초거대 AI 플랫폼을 기반으로 초거대 AI 경쟁력을 강화하면서 미래 전략 산업으로 육성하겠다”고 말했다.






