
.png)





네이버 이해진 글로벌투자책임자(GIO)가 21일 오후 AI서울 정상회의 정상 세션에 참석해 미래 세대가 사용할 안전한 인공지능(AI)을 위해선 각 문화의 가치를 존중하는 다양한 AI 모델들이 등장해야 한다고 밝힌 가운데, 한국 문화를 이해하는 LLM은 하이퍼클로바X라는 사실이 확인된 것이다.
|

|
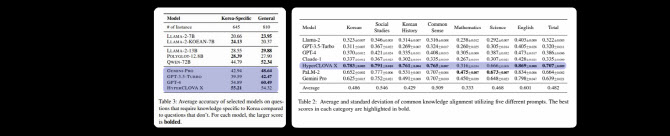
韓 문화에 강한 하이퍼클로바, 2위는 제미나이 프로
22일 업계에 따르면 KorNAT(한국어 데이터셋)에서 여러 LLM을 테스트한 결과. 한국어뿐 아니라 사회학, 한국역사, 상식 등에서 네이버 하이퍼클로바X가 가장 높은 점수를 받았다. KorNAT은 데이터 전문기업 셀렉트스타가 한국과학기술원(KAIST) 김재철AI 대학원과 함께 만든 데이터셋이다.
이 평가는 모델의 평균과 표준 편차를 통해 한국어 능력을 측정한다. 국어, 사회, 한국사, 상식 등을 점수를 매긴다.
이에 따르면 하이퍼클로바X는 국어 0.783±0.0005, 사회 0.791±0.0005, 한국사 0.761±0.0004, 상식 0.765±0.0007을 받아 1위를 차지했다.
GPT-4는 국어 0.370±0.0028, 사회 0.461±0.0028, 한국사 0.335±0.0048, 상식 0.348±0.0065이었고, 제미나이 프로는 국어 0.625±0.0015, 사회0.752±0.0021, 한국사 0.491±0.009, 상식 0.707±0.0010이었다.
람다2는 국어 0.323±0.0008, 사회 0.346±0.0023, 한국사 0.314±0.0017, 상식 0.316±0.008이었고, 무료인 GPT3.5는 국어 0.311±0.0006, 사회0.367±0.0021, 한국사에서 0.269±0.0027, 상식에서 0.324±0.0017을 받았다.
국어 평가뿐 아니라, 사회나 한국사, 상식에서도 하이퍼클로바X가 GPT-4, 제미나이 프로 등을 제친 것이다.
|

이해진 “다양한 AI모델로 각국 문화 지켜야”
이해진 GIO는 지난 21일 AI 서울 정상회의에서 정상세션에 참가해 “사용자들이 다양한 검색 결과에서 정보를 선택하는 것과 달리, AI는 바로 답을 제시하여 선택의 여지가 없다”며 “이러한 AI의 특성은 특히 어린이와 청소년들에게 큰 영향을 미칠 것이며, AI 안전성에서 중요한 고려 사항”이라고 말했다.
그는 “극소수 AI가 현재를 지배하면 역사와 문화에 대한 인식이 그 AI의 답으로만 이뤄지게 되어 미래까지 영향을 미칠 것”이라며 “다양한 시각과 각 지역의 문화적, 환경적 맥락을 이해하는 다양한 AI 모델이 필요하다”고 강조했다. 또한 “역사에는 다양한 시각이 존재한다”며 “다양한 AI 모델로 각국의 문화를 지키고 어린이와 청소년들이 올바른 역사관을 가질 수 있다”고 덧붙였다.
|

모스타크 “LLM 거버넌스 문제..다양성 대안은 블록체인”
다양한 AI모델이 필요하다는 주장은 앞서 에마드 모스타크 전 스태빌리티 AI CEO도 언급한 바 있다. 다만, 그는 대안으로 ‘탈중앙화 AI’를 역설했다.
모스타크 전 스태빌리티 AI CEO는 지난달 12일 과학기술정보통신부가 주최한 ‘글로벌 AI 안전 컨퍼런스’에서 거대언어모델(LLM)의 데이터셋을 만드는 과정에서 치우침이 불가피하다고 밝혔다. 그는 “엔트로픽 같은 경우 언어가 충분치 않으면 파인튜닝 자체가 되지 않으며, 대부분 영어에 기반한다”며 “이런 기본 구조의 거버넌스와 코디네이션도 문제”라고 설명했다.
또한 “대부분의 LLM들이 영어에 기반하기 때문에 다양한 국가들이 프로토콜에 참여하기 어렵고, 결과물에 대한 제어도 쉽지 않다”고 덧붙였다. 이어 “오픈소스는 괜찮지만, 미얀마나 인도네시아 같은 나라들은 LLM에 참여할 기회가 부족하다”며 “국가 언어에 맞춘 LLM이 필요하고, 자국법에 적용될 수 있는 규제도 필요하다”고 강조했다.
모스타크는 AI 모델의 다양성에 대한 대안으로 블록체인 기술을 언급했다. 그는 “블록체인이나 웹3에서는 사람들이 투표해 분산 원장을 만든다. 마찬가지로 투표권을 가진 사람들이 AI의 투명성을 검증할 수 있을 것”이라며 “AI는 훈련에 표준이 필요하고, 이를 위해 블록체인 기술이 유용하다”고 설명했다.
그는 “AI는 데이터의 질에 따라 결과물이 달라지며 안전성도 결정된다. 어떤 데이터가 모델에 들어가고 있는지 투명성을 확보하고, 데이터가 각 주체를 제대로 대표하는지도 확인해야 한다”고 말했다.
|

|

하이퍼클로바X, 중동·동남아 공략
네이버는 미국과 중국의 빅테크들 속에서 글로벌 소버린 AI 생태계 진출 기회를 노리고 있다. 소버린 AI란 한 국가가 자체 인프라, 데이터, 인력, 비즈니스 네트워크를 사용해 AI를 생산하는 역량을 말한다.
미국의 그래픽처리장치(GPU)와 AI 칩 통제, 틱톡 금지, 프랑스와 중국의 AI 안전 협력 같은 국제 정세 변화 속에서 네이버는 태국, 필리핀 같은 동남아 시장을 공략하고 중동 시장에 전략적으로 진출할 계획이다.
이해진 GIO는 “구체화된 AI 안전 실행 프레임워크인 NAVER AI Safety Framework를 다음 달 공개할 예정”이라며 “네이버는 각 지역의 문화와 가치를 존중하고 이해하며, 책임감 있는 다양한 AI 모델들이 많은 글로벌 국가들이 자체 소버린 AI를 확보할 수 있도록 기술로 지원할 것”이라고 밝혔다.
하정우 네이버클라우드 AI 이노베이션 센터장은 21일 ‘하이퍼클로바X 레퍼런스 세미나’에서 “미국은 칩스법으로 인텔에 100억 달러를 투자하고, TSMC나 삼성전자 같은 외국 기업도 미국 내 공장을 짓는다고 하면 보조금을 준다. 일본도 최근 3700억 원을 추가 투자해 거의 4500억 원을 소프트뱅크에 지급했다. 프랑스도 미스트랄AI를 적극적으로 지원한다”면서 “중동 국가들 역시 큰 관심을 보이고 있다”고 전했다.
또한 그는 “엔비디아 독점 상황을 해소하기 위해 인텔과 함께 ‘가우디(NPU)’ 생태계를 넓혀 학습용 수요에 대응하고, 삼성전자와는 저전력 고효율 저비용의 추론용 AI 반도체(마하-1, FPGA)에서 협력하고 있다”며 “생성형 AI는 한 기업이 혼자 시장을 개척하기 어렵다. 프로덕트를 만들고 데이터를 추가하며 구축하고 가공하고 문제를 정리하고 컨설팅하는 많은 파트너 기업들의 역할이 매우 중요하다. 이것이 생태계를 강화하고 우리의 경쟁력을 높이는 길”이라고 언급했다.
|





![컴맹 어르신도 불장 참전…5대銀 ETF 석달새 22.5조 불티[only이데일리]](https://image.edaily.co.kr/images/vision/files/NP/S/2026/05/PS26050800309t.jpg)

